The IT’S A DIVE project ends up with a bang! The article “Estimation of spectral notches from pinna meshes: Insights from a simple computational model” (S. Spagnol, R. Miccini, M.G. Onofrei, R. Unnthorsson, S. Serafin) was recently published in the prestigious IEEE/ACM Transactions on Audio, Speech, and Language Processing. An early access version of the article is currently available at the following URL: https://doi.org/10.1109/TASLP.2021.3101928.
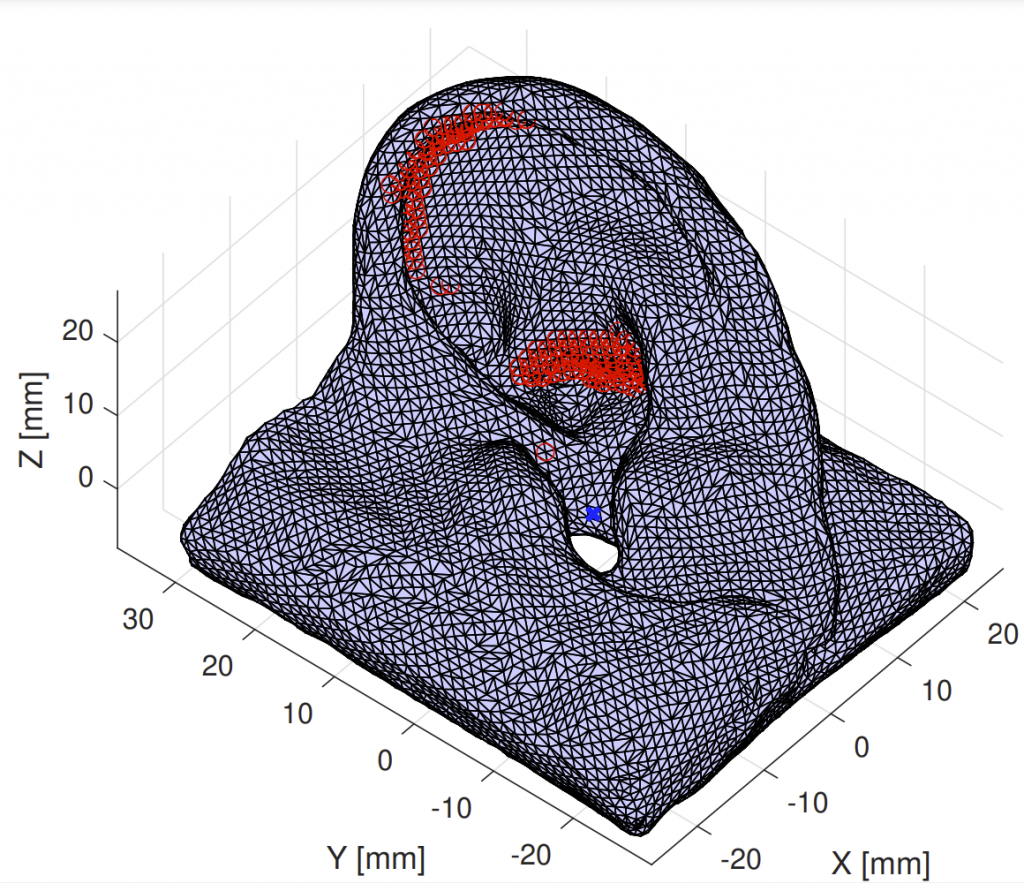
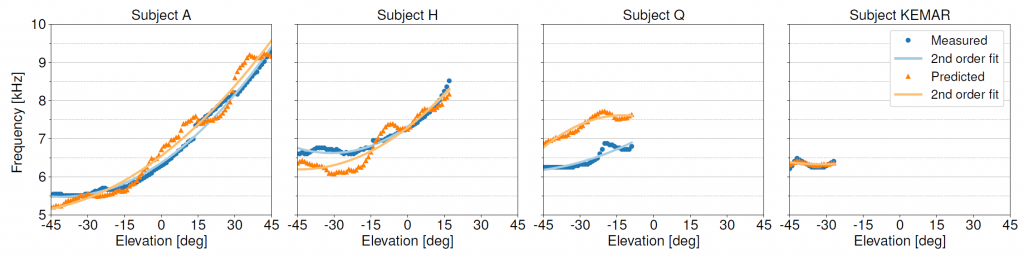
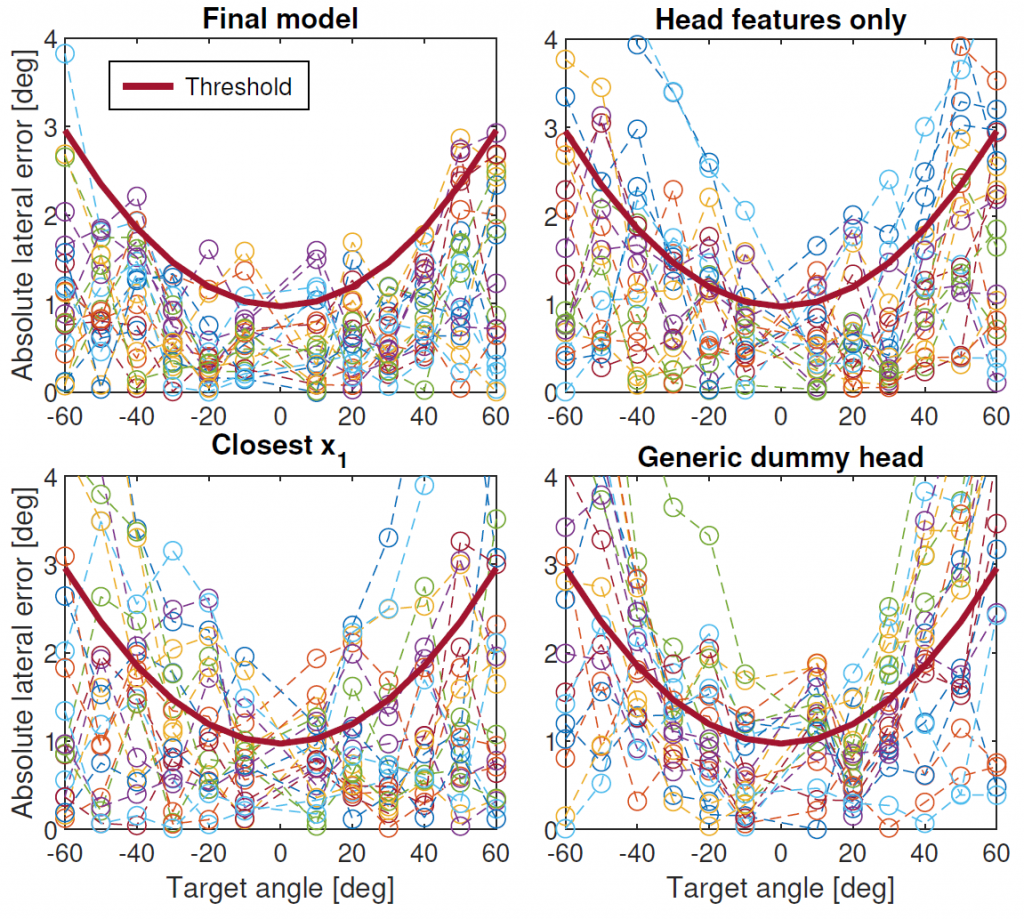
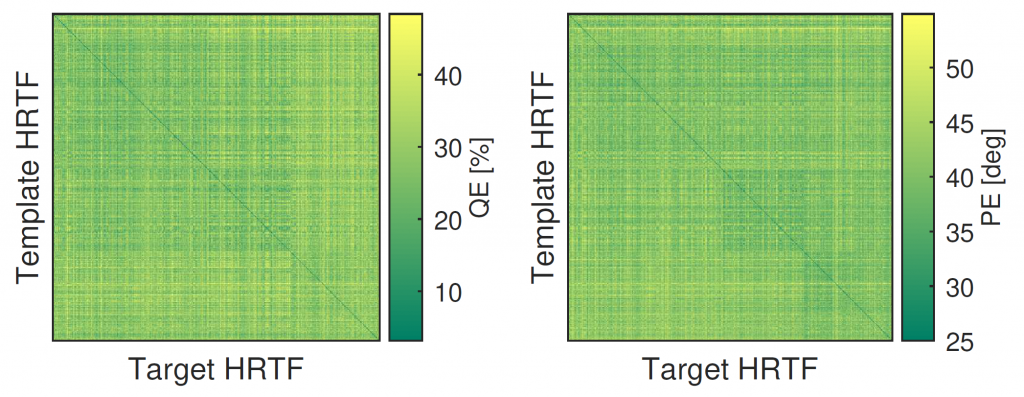
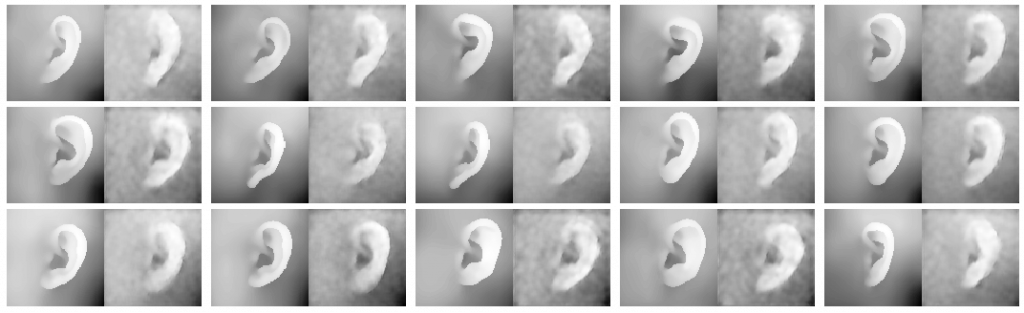
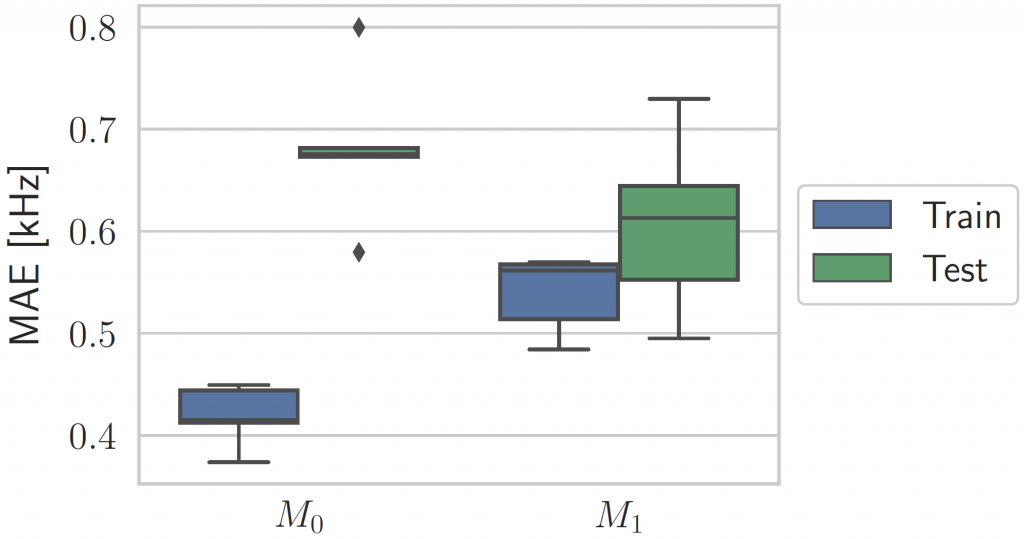
While previous research on spatial sound perception investigated the physical mechanisms producing the most relevant elevation cues, how spectral notches are generated and related to the individual morphology of the human pinna is still a topic of debate. Correctly modeling these important elevation cues, and in particular the lowest frequency notches, is an essential step for individualizing Head-Related Transfer Functions (HRTFs). In this paper we propose a simple computational model able to predict the center frequencies of pinna notches from ear meshes. We apply such a model to a highly controlled HRTF dataset built with the specific purpose of understanding the contribution of the pinna to the HRTF. Results show that the computational model is able to approximate the lowest frequency notch with improved accuracy with respect to other state-of-the-art methods. By contrast, the model fails to predict higher-order pinna notches correctly. The proposed approximation supplements understanding of the morphology involved in generating spectral notches in experimental HRTFs.