Our I3DA paper “Evaluation of individualized HRTFs in a 3D shooter game” (J.S. Andersen, R. Miccini, S. Serafin, S. Spagnol) has finally been published and added to the IEEE Xplore® library. You can find it here.
This announcement officially concludes the activities related to IT’S A DIVE. We would like to thank the European Union for making our project possible, and hope that our efforts will inspire amazing new research in the fields of spatial audio technologies and virtual environments.
On Wednesday, September 8th, our student Jonas Siim Andersen presented the final paper from IT’S A DIVE, “Evaluation of individualized HRTFs in a 3D shooter game” (J.S. Andersen, R. Miccini, S. Serafin, S. Spagnol), at the 1st International Conference on Immersive and 3D Audio. The conference has been an entirely virtual event, with about 120 registered participants attending the presentation. The conference proceedings will be submitted by the organizers to the IEEE Xplore Digital Library. In the meantime, you can watch Jonas’ recorded presentation here.
The final version of the IEEE/ACM Transactions on Audio, Speech, and Language Processing article “Estimation of spectral notches from pinna meshes: Insights from a simple computational model” (S. Spagnol, R. Miccini, M.G. Onofrei, R. Unnthorsson, S. Serafin) is now available in open access at the following URL: https://ieeexplore.ieee.org/document/9507273.
The IT’S A DIVE project ends up with a bang! The article “Estimation of spectral notches from pinna meshes: Insights from a simple computational model” (S. Spagnol, R. Miccini, M.G. Onofrei, R. Unnthorsson, S. Serafin) was recently published in the prestigious IEEE/ACM Transactions on Audio, Speech, and Language Processing. An early access version of the article is currently available at the following URL: https://doi.org/10.1109/TASLP.2021.3101928.
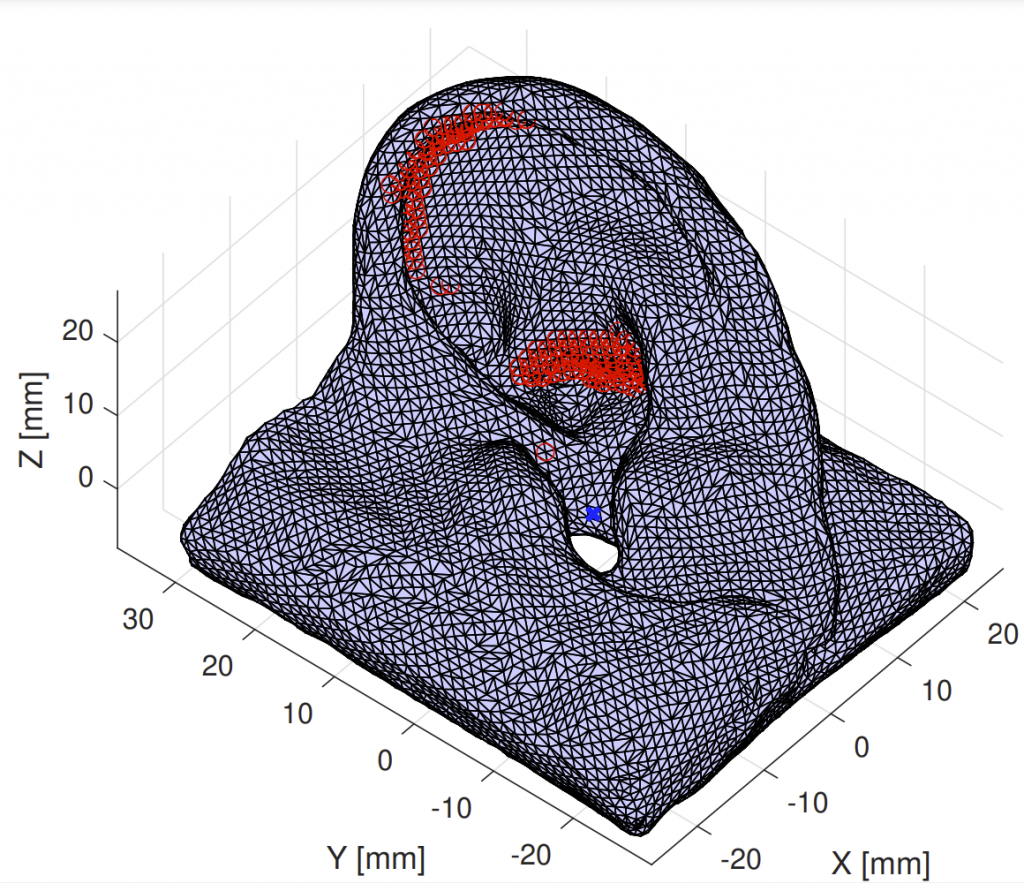
3D mesh of a left pinna and selected vertices (red) for a representative elevation angle.
While previous research on spatial sound perception investigated the physical mechanisms producing the most relevant elevation cues, how spectral notches are generated and related to the individual morphology of the human pinna is still a topic of debate. Correctly modeling these important elevation cues, and in particular the lowest frequency notches, is an essential step for individualizing Head-Related Transfer Functions (HRTFs). In this paper we propose a simple computational model able to predict the center frequencies of pinna notches from ear meshes. We apply such a model to a highly controlled HRTF dataset built with the specific purpose of understanding the contribution of the pinna to the HRTF. Results show that the computational model is able to approximate the lowest frequency notch with improved accuracy with respect to other state-of-the-art methods. By contrast, the model fails to predict higher-order pinna notches correctly. The proposed approximation supplements understanding of the morphology involved in generating spectral notches in experimental HRTFs.
Our paper “Evaluation of individualized HRTFs in a 3D shooter game” (J.S. Andersen, R. Miccini, S. Serafin, S. Spagnol) has been accepted for presentation at the 1st International Conference on Immersive and 3D Audio that will be held fully virtually on September 8-10, 2021. We will be there to present the final results of IT’S A DIVE.
Two clusters of targets within the first-person shooter game.
The paper proposes a method of using in-game metrics to test the hypothesis that individualized HRTFs improve the experience of both expert and novice players in a First-Person Shooter (FPS) game on a desktop environment. The FPS game provides players with a localization task across three different audio renderings using the same acoustic spaces: stereo panning (control condition), generic binaural rendering, and individualized binaural rendering. Collected metrics from the game include localization error, spatial quality attributes, and an extensive questionnaire.
The individualized HRTFs for each participant were synthesized using the hybrid structural model described in our previous publication. Results show that the 22 participants performed significantly better in the localization task with their individualized HRTF. Increased localization accuracy with respect to the generic HRTF was recorded both in azimuth and elevation perception, and especially in the case of expert game players.
Last Saturday, Riccardo presented the paper “A hybrid approach to structural modeling of individualized HRTFs” (R. Miccini, S. Spagnol) at the IEEE 6th VR Workshop on Sonic Interactions in Virtual Environments, as part of the 28th IEEE Conference on Virtual Reality and 3D User Interfaces (IEEE VR 2021). Like last year the conference has been an entirely virtual event, and the workshop was live-streamed for free. About 80 participants attended the workshop. You can watch the recorded presentation here (starting at 01:58:43) and download the final version of the paper here.
The paper presents a hybrid approach to individualized head-related transfer function (HRTF) modeling which requires only 3 anthropometric measurements and an image of the pinna. A prediction algorithm based on variational autoencoders synthesizes a pinna-related response from the image, which is used to filter a measured head-and-torso response. The interaural time difference is then manipulated to match that of the HUTUBS dataset subject minimizing the predicted localization error. The results are evaluated using spectral distortion and an auditory localization model. While the latter is inconclusive regarding the efficacy of the structural model, the former metric shows promising results with encoding HRTFs.
Our project is featured in this month’s edition (Vol. 8) of the Project Repository Journal (PRj).
PRj is the European Dissemination Media Agency’s flagship open access publication dedicated to showcasing funded science and research throughout Europe. It is distributed quarterly to a global audience of over 200,000 people, with features discussing current and future funding calls, science policy, European and World-Wide Initiatives and research news.
Check out the full article inside PRj Vol. 8 or in pdf!
It is our pleasure to announce that the Viking HRTF dataset v2 is now available in open access!
The Viking HRTF dataset v2 is a collection of head-related transfer functions (HRTFs) measured at the University of Iceland. It includes full-sphere HRTFs measured on a dense spatial grid (1513 positions) with a KEMAR mannequin with different pairs of artificial pinnae attached.
The 20 pairs of 35 Shore OO silicone pinna replicas
A first version of the dataset had been released in May 2019. In this second version, the used artificial pinnae were re-casted from the existing inverse molds with 35 Shore OO silicone for both the left and right channels of the KEMAR. Furthermore, the HRTF measurements have been taken inside the anechoic chamber of the University of Iceland in Reykjavík and free-field compensated.
The HRTF measurement setup
The dataset, available in SOFA format, contains measurements for 20 different pairs of artificial pinna replicas (subjects A to T, where T is a pair of standard large KEMAR anthropometric pinnae replicas) plus a pair of flat baffles simulating a “pinna-less” condition (subject Z). 3D scans of the 20 left pinna replicas are also included.
More information is available on the official page of the dataset on Zenodo.
The conference, organized by three institutions from Torino, Italy together with Aalborg University, has been an entirely free virtual event broadcasted on YouTube on June 24-26. Day 1 had a total number of over 1,500 views. You can watch all the conference sessions on demand on the SMC 2020 YouTube channel.
Our paper “3D ear shape as an estimator of HRTF notch frequency” (M.G. Onofrei, R. Miccini, R. Unnthórsson, S. Serafin, S. Spagnol) has been accepted for presentation at the 17th Sound and Music Computing Conference that will be held fully virtually on June 24-26, 2020. The conference has members of IT’S A DIVE among its organizers, and will feature this year a dedicated oral session on spatial sound.
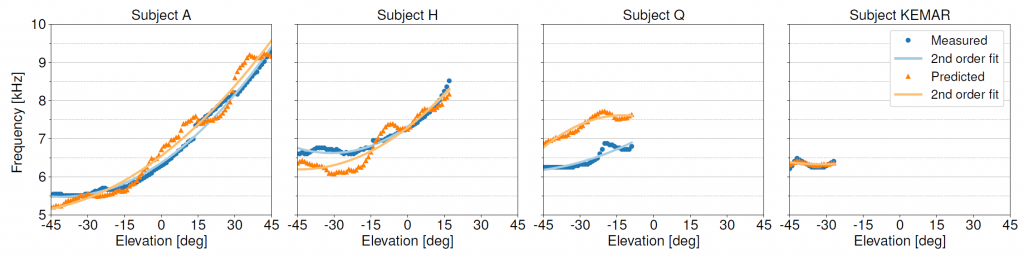
Measured and predicted N1 tracks for four test subjects.
The paper makes use of a new dataset of HRTFs (cfr. previous post) containing high resolution median-plane acoustical measurements of a KEMAR mannequin with 20 different left pinna models as well as 3D scans of the same pinna models. This allows for an investigation of the relationship between 3D ear features and the first pinna notch N1 present in the HRTFs. We propose a method that takes the 3D pinna mesh and generates a dataset of depth maps of the pinna viewed from various median-plane elevation angles, each having an associated pinna notch frequency value as identified in the HRTF measurements. A multiple linear regression model is then fit to the depth maps, aiming to predict the corresponding N1. The results of the regression model show moderate improvement to similar previous work built on global and elevation-dependent anthropometric pinna features extracted from 2D images.