Last week Simone presented his paper “Auditory model based subsetting of head-related transfer function datasets ” at the 45th IEEE International Conference on Acoustics, Speech, and Signal Processing (IEEE ICASSP 2020) . The conference has been an entirely free virtual event, with an exceptional number of more than 14,000 participants attending the technical content. You can watch again the presentation and access the paper here (until June 8, 2020).
The final version of the IEEE Signal Processing Letters article “HRTF selection by anthropometric regression for improving horizontal localization accuracy” (S. Spagnol) is now available in open access at the following URL: https://ieeexplore.ieee.org/document/9050904.
The paper “Auditory model based subsetting of head-related transfer function datasets” (S. Spagnol) is now available in IEEE Xplore® as an Open Preview article. You can download it for free until May 08, 2020 at this link: https://ieeexplore.ieee.org/document/9053360.
The article “HRTF selection by anthropometric regression for improving horizontal localization accuracy” (S. Spagnol) was recently accepted for publication in the IEEE Signal Processing Letters. An early access version of the article is currently available at the following URL: https://ieeexplore.ieee.org/document/9050904. It will be made open access in its final version.
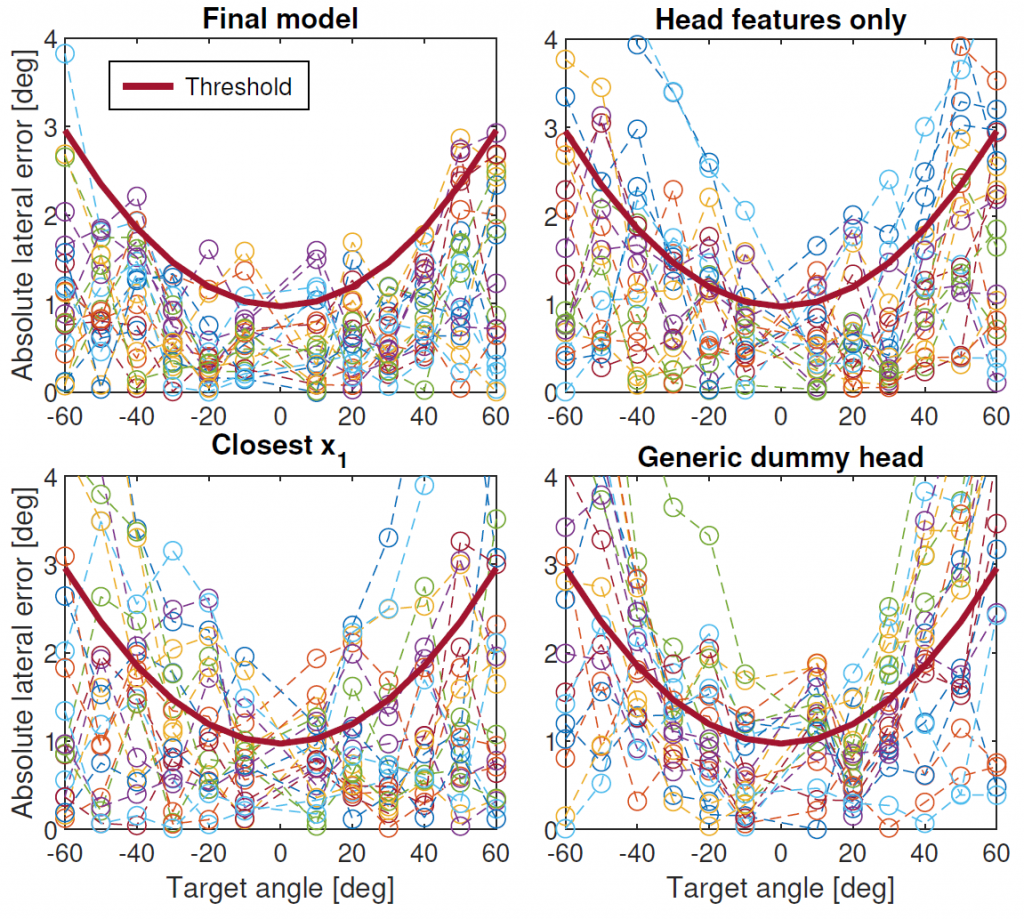
Absolute lateral error for test set subjects with non-individual HRTFs: (1) best fitting HRTF according to the final regression model (top left), (2) best fitting HRTF according to an alternative regression model on the head dimensions only (top right), (3) HRTF selected by closest head width (bottom left), and (4) FABIAN dummy head HRTF (bottom right). Solid curves represent the approximate localization blur threshold.
The article focuses on objective HRTF selection from anthropometric measurements for minimizing localization error in the frontal half of the horizontal plane. Localization predictions for every pair of 90 subjects in the HUTUBS database are first computed through an interaural time difference-based auditory model, and an error metric based on the predicted lateral error is derived. A multiple stepwise linear regression model for predicting error from inter-subject anthropometric differences is then built on a subset of subjects and evaluated on a complementary test set. Results show that by using just three anthropometric parameters of the head and torso (head width, head depth, and shoulder circumference) the model is able to identify non-individual HRTFs whose predicted horizontal localization error generally lies below the localization blur. When using a lower number of anthropometric parameters, this result is not guaranteed.
Last Sunday, we presented the paper “HRTF individualization using deep learning” (R. Miccini, S. Spagnol) at the IEEE 5th VR Workshop on Sonic Interactions in Virtual Environments, as part of the 27th IEEE Conference on Virtual Reality and 3D User Interfaces (IEEE VR 2020). Due to the pandemic outbreak, the conference has been an entirely virtual event, and the workshop was live-streamed for free. You can watch the recorded presentation here (starting at 01:46:30) and download the final version of the paper here.
The new year kicks off with two paper acceptances. “Auditory model based subsetting of head-related transfer function datasets” (S. Spagnol) will be presented at the 45th IEEE International Conference on Acoustics, Speech, and Signal Processing (IEEE ICASSP 2020) taking place in Barcelona, Spain in May. We will also be in Atlanta, US next month at the IEEE 5th VR Workshop on Sonic Interactions in Virtual Environments with the paper “HRTF individualization using deep learning” (R. Miccini, S. Spagnol), as part of the 27th IEEE Conference on Virtual Reality and 3D User Interfaces (IEEE VR 2020).
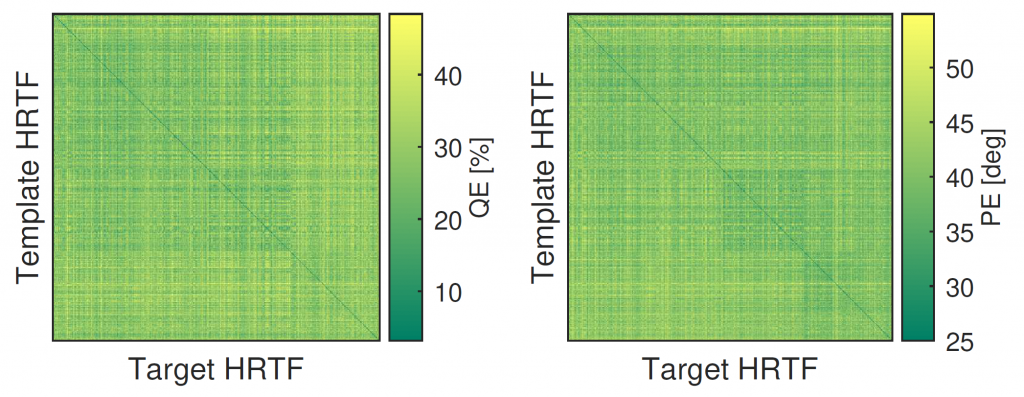
Quadrant error rate (QE) and root mean square local polar error (PE) matrices for the 373 catalogue subjects.
The former paper outlines a novel HRTF subset selection algorithm based on auditory-model vertical localization predictions and a greedy heuristic to identify an optimal subset of representative HRTFs from a catalogue including the three biggest open HRTF datasets currently available online (see figure above). An objective validation of the optimal subset on a fourth independent dataset, based again on auditory model predictions, is provided. The results show an overwhelming agreement on the choice of this optimal subset, supporting the idea that a large HRTF catalogue can be efficiently reduced by two orders of magnitude while preserving at least one HRTF fitting the very large majority of a pool of listeners in terms of localization error.
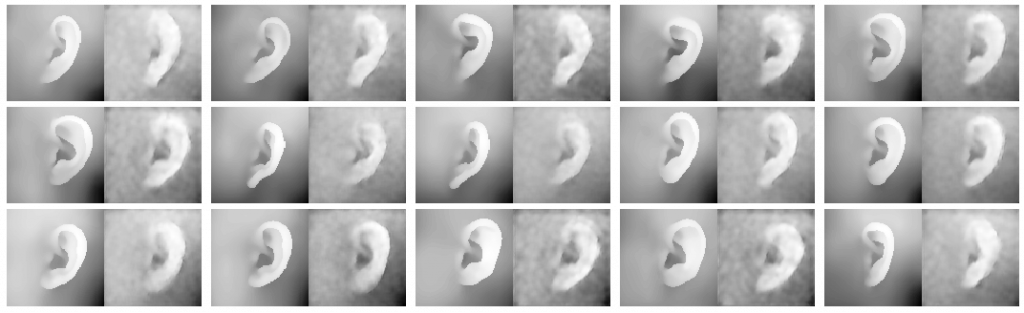
True and reconstructed pinna depth maps using a convolutional variational autoencoder.
The research presented in the latter paper focuses on HRTF individualization using deep learning techniques. The rising availability of public HRTF data currently allows experimentation with different input data formats and various computational models. Accordingly, three research directions are investigated: (1) extraction of predictors from user data (see figure above) ; (2) unsupervised learning of HRTFs based on autoencoder networks; and (3) synthesis of HRTFs from anthropometric data using deep multilayer perceptrons. While none of the aforementioned investigations has shown outstanding results to date, the knowledge acquired throughout the development and troubleshooting phases highlights areas of improvement which are expected to pave the way to more accurate models for HRTF individualization.
During the past month we have been working on the collection of a new set of HRTF measurements with the KEMAR mannequin. The measurements have been taken inside the recently built anechoic chamber at the University of Iceland, Reykjavík.
HRTF measurement setup inside the new University of Iceland anechoic chamber.
The new measurements are analogous to those included in the published Viking HRTF dataset. The main differences lie in the measurement environment (previously non-anechoic) and in the production of a sample that includes both left and right pinnae made out of soft (Shore 00-35) silicone. The new set of measurements will serve as an even stronger basis for our HRTF modelling stage.
Over the past week, the project was present at two events – first, within a seminar targeted at Master students and researchers in computer science at the University of Milano, Italy, where Simone presented an overview of the project contents and goals.
Then, our student Riccardo presented the paper Estimation of pinna notch frequency from anthropometry: an improved linear model based on Principal Component Analysis and feature selection (R. Miccini, S. Spagnol) at the 1st Nordic Sound and Music Computing Conference in Stockholm, Sweden. About 50 international researchers, mostly from Nordic European countries, attended the conference. You can download the final proceedings version of the paper here.
Our paper “Estimation of pinna notch frequency from anthropometry: an improved linear model based on Principal Component Analysis and feature selection” (R. Miccini, S. Spagnol) has been accepted for presentation at the 1st Nordic Sound and Music Computing Conference that will take place in Stockholm, Sweden next month.
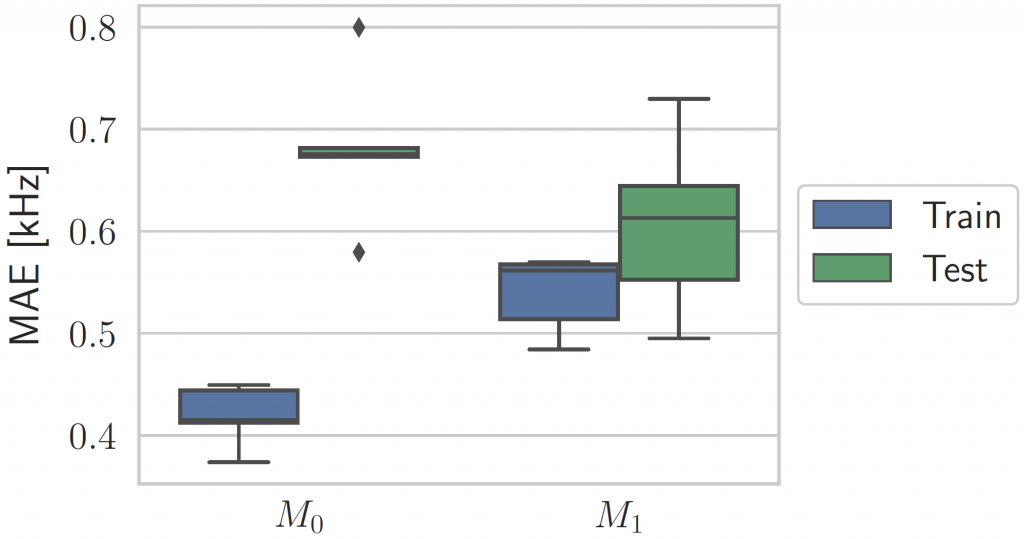
Box-and-whisker plot showing the mean absolute error (expressed in kHz) of baseline model M0 and the proposed model M1, for training and test sets respectively.
In the paper, anthropometric data from a database of HRTFs is used to estimate the frequency of the first pinna notch in the frontal part of the median plane. Given the presence of high correlations between some of the anthropometric features, as well as repeated values for the same subject observations, we propose the introduction of Principal Component Analysis (PCA) to project the features onto a space where they are more separated. We then construct a regression model employing forward step-wise feature selection to choose the principal components most capable of predicting notch frequencies. Our results show that by using a linear regression model with as few as three principal components (M1 in the above plot), we can predict notch frequencies with a cross-validation mean absolute error of just about 600 Hz.
On May 29, 2019 we were in Málaga at the 16th Sound and Music Computing Conference, annual forum of the international Sound and Music Computing Community, to present the first project-funded work, The Viking HRTF dataset (S. Spagnol, K.B. Purkhús, S.K. Björnsson, R. Unnthórsson). You can download the final proceedings version of the corresponding article here.
The work we presented – in poster format – is about the collection and evaluation of the HRTF dataset described in our previous post. About 100 international researchers attended the conference.